在使用 Filebeat 收集系统日志时,有些网络设备的日志是通过 UDP 端口接收的,并且有多个 Filebeat 实例在使用不同的 UDP 端口同时运行。为了保证日志的完整性,避免因 Filebeat 意外停止导致数据丢失,需要监控其运行状态。首先想到的是 process_exporter,但在调研后发现,它对同名多个进程的监控配置较为复杂,难以满足需求。另一个方案是使用 blackbox_exporter 监控 Filebeat 所用端口,但深入研究后发现 blackbox_exporter 并不支持 UDP 端口探测。于是决定自己动手写一个 exporter。
键盘拿来
prometheus_client 是 Prometheus 的官方 Python 客户端,安装和使用方法详见官方文档。以下是我的第一版代码:
import os
from flask import Flask, Response, redirect
from prometheus_client import generate_latest, CollectorRegistry, Gauge
app = Flask(__name__)
registry = CollectorRegistry(auto_describe=False)
'''创建一个仓库装收集到的指标'''
@app.route('/metrics')
def hello():
port_list = [6984, 6985, 6998, 7878, 7879, 7880, 618, 8814, 8815, 8816, 8817, 8818, 8819, 718, 815]
for i in port_list:
shell = "netstat -unlp |awk -F: '{print $4}'|grep ^%s |wc -l" % i
command = os.popen(shell)
command = command.read()
gauge = Gauge('Port{}'.format(i), 'show filebeat UDP port status', ['Port'], registry=registry)
gauge.labels('{}'.format(i)).set(float(command))
return Response(generate_latest(registry), mimetype='text/plain')
@app.route('/')
def index():
return redirect("/metrics")
'''根路由重定向到/metrics'''
if __name__ == '__main__':
app.run(host='0.0.0.0', port=9117)
这是第一版实现,使用了 Flask、prometheus_client 和 os 模块。为了便于后续新增端口时不需大幅修改代码,我把所有监控端口集中放在一个列表中。然而,这个版本存在一个致命问题:无法刷新 /metrics 页面。一旦刷新,就会重新触发路由逻辑,导致 Gauge 指标重复注册,抛出错误:
Duplicated timeseries in CollectorRegistry: {'Port6984'}
这表示 CollectorRegistry 中出现了重复的时间序列。我尝试寻找清空 CollectorRegistry 的方法,查阅文档后尝试使用 REGISTRY.unregister() 来取消注册,但几番搜索仍未成功解决。虽然 Gauge 对象提供了 clear() 方法,但实际效果不符合预期,最终放弃此方案。
无奈之下另辟蹊径:通过定时重启 Flask 脚本来重置指标状态,使 Prometheus 采集时能获取最新数据。
将 Flask 项目配置为 systemd service,便于管理与重启:
[root@filebeat ~]# cat /usr/lib/systemd/system/flask_exporter.service
[Unit]
Description=flask_exporter.server
After=network.target
[Service]
ExecStart=/usr/bin/python3 /etc/flask_exporter.py
Restart=on-failure
[Install]
WantedBy=multi-user.target
再通过 crontab 定时重启该服务。由于 crontab 最小粒度为每分钟一次,为实现更高频率的“刷新”,参考网上思路,使用 sleep 错峰执行:
* * * * * systemctl restart flask_exporter.service
* * * * * sleep 10; systemctl restart flask_exporter.service
* * * * * sleep 20; systemctl restart flask_exporter.service
* * * * * sleep 30; systemctl restart flask_exporter.service
* * * * * sleep 40; systemctl restart flask_exporter.service
* * * * * sleep 50; systemctl restart flask_exporter.service
总算用“歪门邪道”解决了问题,折腾良久。
还能优化
后来在阅读他人代码时发现了更优雅的做法,于是重新尝试优化。修改后的代码如下:
import os
import prometheus_client
from prometheus_client import start_http_server, Gauge
prometheus_client.REGISTRY.unregister(prometheus_client.PROCESS_COLLECTOR)
prometheus_client.REGISTRY.unregister(prometheus_client.PLATFORM_COLLECTOR)
prometheus_client.REGISTRY.unregister(prometheus_client.GC_COLLECTOR)
'''取消注册prometheus_client默认会收集的没啥用的数据,这样指标页面就没这些垃圾了。'''
UDP_PORT = Gauge("PORT", "show port status", ['label'])
'''创建一个我们自己的指标,类型是Gauge'''
if __name__ == '__main__':
start_http_server(9117)
'''开启http暴露指标,端口在9117'''
while True:
port_list = [6984, 6985, 6998, 7878, 7879, 7880, 618, 8814, 8815, 8816, 8817, 8818, 8819, 718, 815]
for i in port_list:
shell = "netstat -unlp |awk -F: '{print $4}'|grep ^%s |wc -l" % i
'''在脚本所在的机器上执行如下命令,如果端口存活,wc的结果就是1,其他任何值都是不正常的。'''
command = os.popen(shell)
command = command.read()
'''获取shell的执行结果'''
UDP_PORT.labels("{}".format(i)).set(int(command))
'''将i的值传递给这个UDP_PORT的label,并将command的值转换后赋值给UDP_PORT这个指标'''
将指标暴露方式由 Flask 改为 prometheus_client 自带的 start_http_server,减少外部依赖。
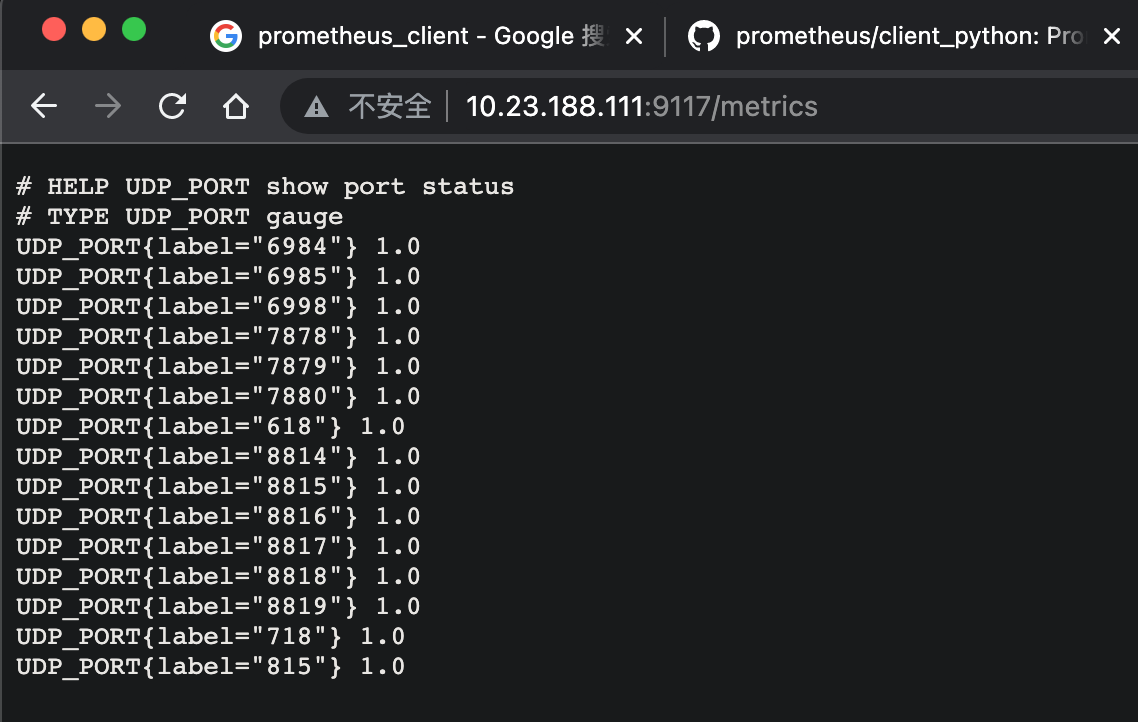
这一版本彻底解决了 /metrics 页面无法刷新的问题——因为不再使用独立的 CollectorRegistry,而是直接复用全局 REGISTRY,并通过单一 Gauge 实例配合标签(label)动态更新指标值。所有端口共用同一个指标名 PORT,仅通过 label 区分,这样在编写 Prometheus 告警规则时可以统一匹配:
- alert: UDP_Port_Down
expr: PORT{job="filebeat_exporter"} == 0
for: 1m
labels:
severity: critical
annotations:
summary: "Filebeat UDP port {{ $labels.label }} is down"
一条规则即可覆盖所有端口,无需为每个端口单独写规则。而此前每个端口对应一个独立 metric,既冗余又难以维护。
至此, exporter 实现简洁、稳定、可扩展,真正“跑通了”。