今天中午散步回来,美女同事跟我说,最近的日志没有进来,我登上 Kibana 一看,我靠,近两天的日志全没有(部分索引有,部分索引量变少了,部分索引完全没有新日志进来)。怎么办?看日志呗,毕竟咱不能像美女同事一样把这个情况告诉别人然后摆烂吧,本文记录处理的全流程。
Kibana 看不到日志,说明没进 ES,登录 Logstash 查看 Logstash 日志显示如下:
12 partitions have leader brokers without a matching listener, including [koala-0, SDP_system-0, prometheus-0, network_23_clearpass-0, network_35_Aruba-system-0, aduser_change-0, nuc-0, nginx_test-0, Network_23_RS_Device-0, network_35_zdns-0]
不得不说 Java 程序的日志就是老太太的裹脚布又臭又长,上面只贴了关键部分。
下面介绍一下我的新同事——ChatGPT,不得不说一个拥有全人类知识结晶并且能够理解分析的人工智能很牛逼。至于什么失业,不在本文的讨论范围内,毕竟 AI 只能提供思路,暂时我还不能失业。

现在来分析分析我这位同事的分析:
- 确实是部分分区有 leader broker,但是没有 listener(并且后面列出来了详细的 12 个分区)
- 检查 broker 配置,这个东西正常运行,根本没人会动
- 检查网络连接,这三台 Kafka 组成的集群是在 Azure 上的,出现网络问题的可能性不大吧,将信将疑 ping 了一下,没啥问题
- 检查分区配置,同上,没人动的
下面介绍一个 Kafka 看板工具,kafka-ui 支持展示多集群,支持展示 Brokers、Topics、Consumers。
通过查看 kafka-ui 发现集群中确实有异样:
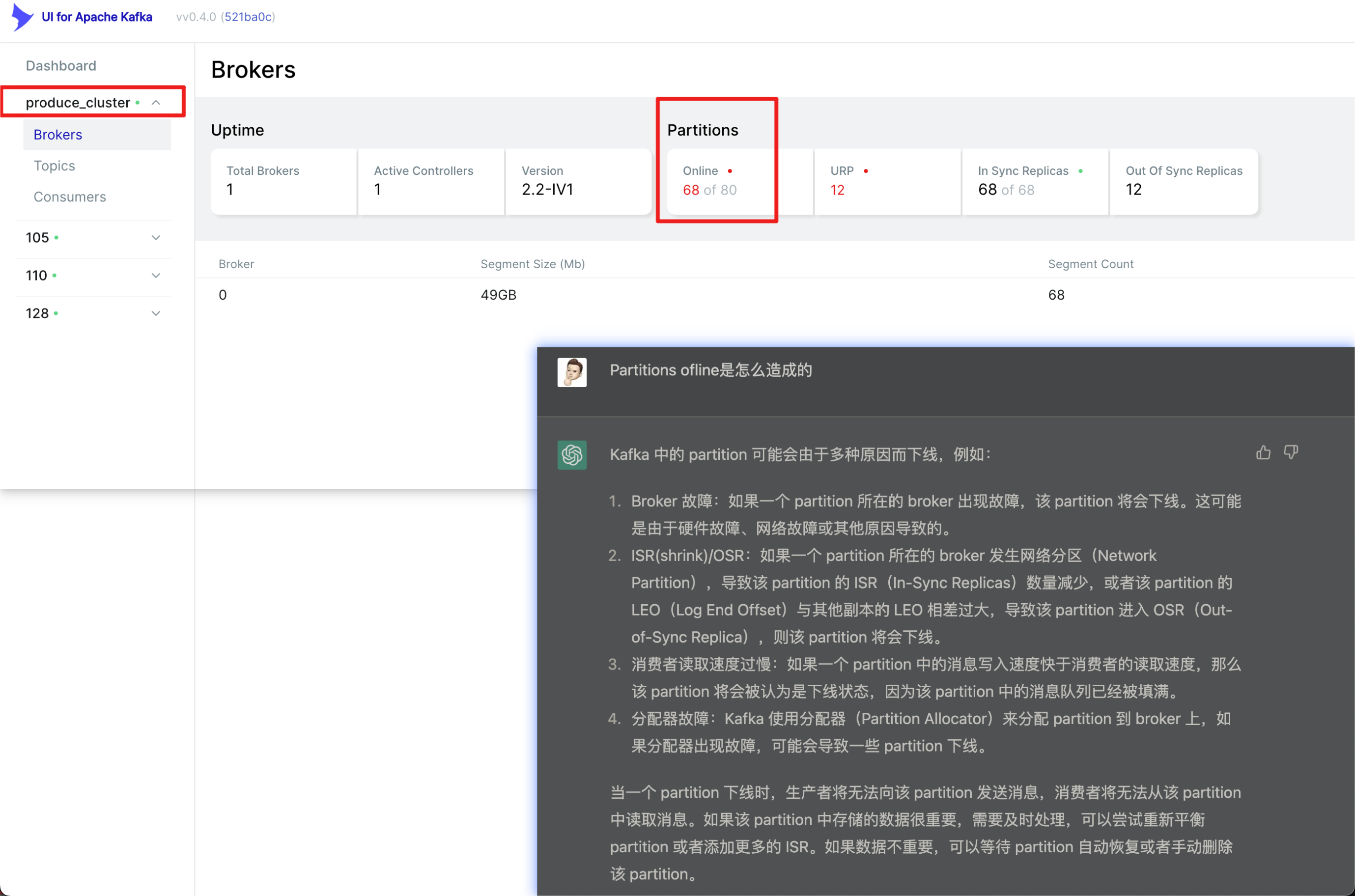
上图圈出来的就是生产集群的 Partitions 异常,显示有 68 个 Online,小脑瓜一转,那不就是有 12 个 offline 吗?12 不就是刚才 Logstash 日志里面报错有 12 个分区异常吗?至于旁边的 URP 刚好也是 12,问问我同事这啥意思?
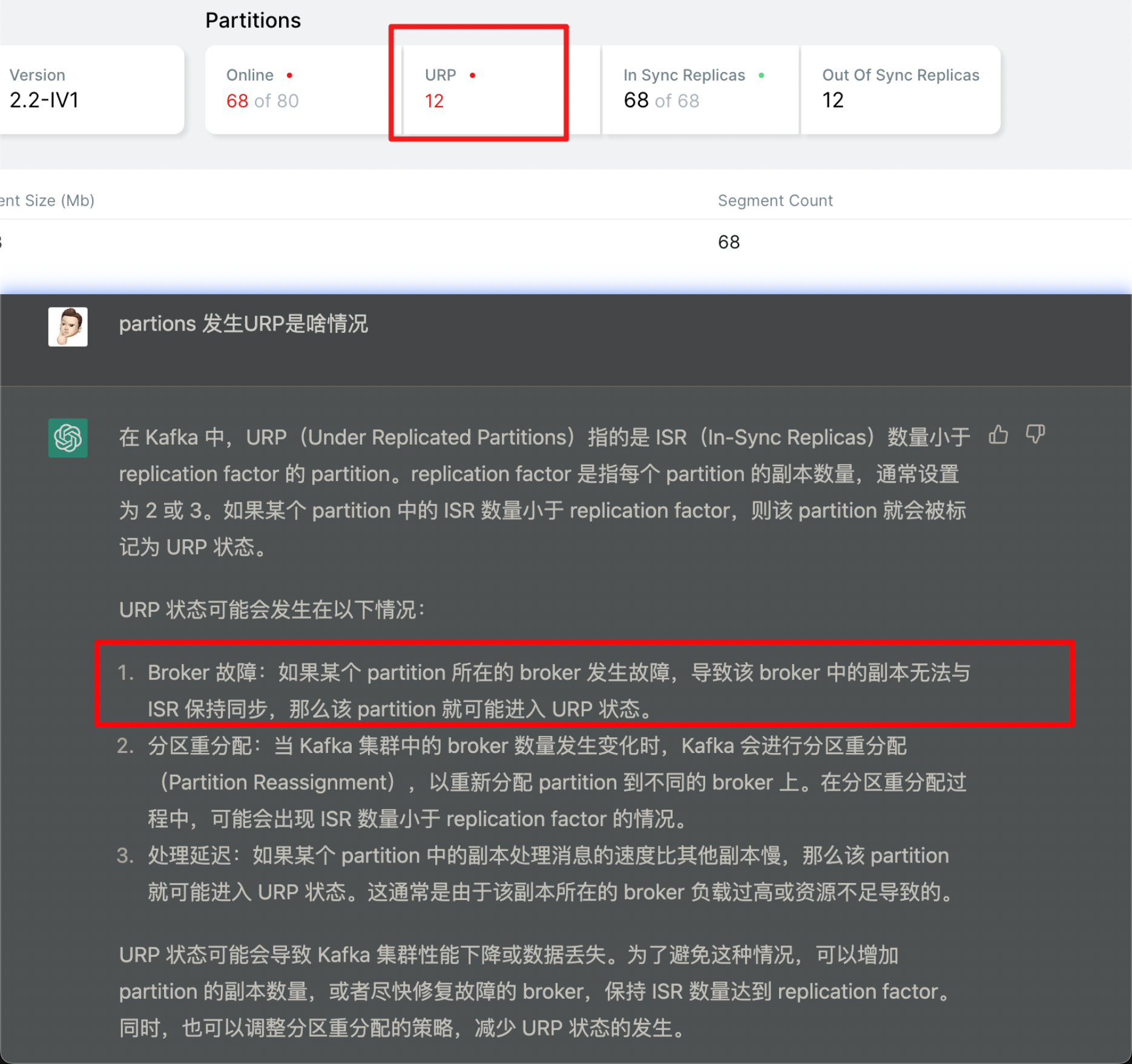
看到没,我同事真牛逼,没三十年运维经验能做到这般对答如流?试问各位看官你们可以吗?
看我画的红圈,根据 Logstash 日志和 kafka-ui,得出大概结论:因为 broker 发生故障导致同步失败,进入 URP 状态,产生 offline Partition。
那么问题来了,怎么解决呢?
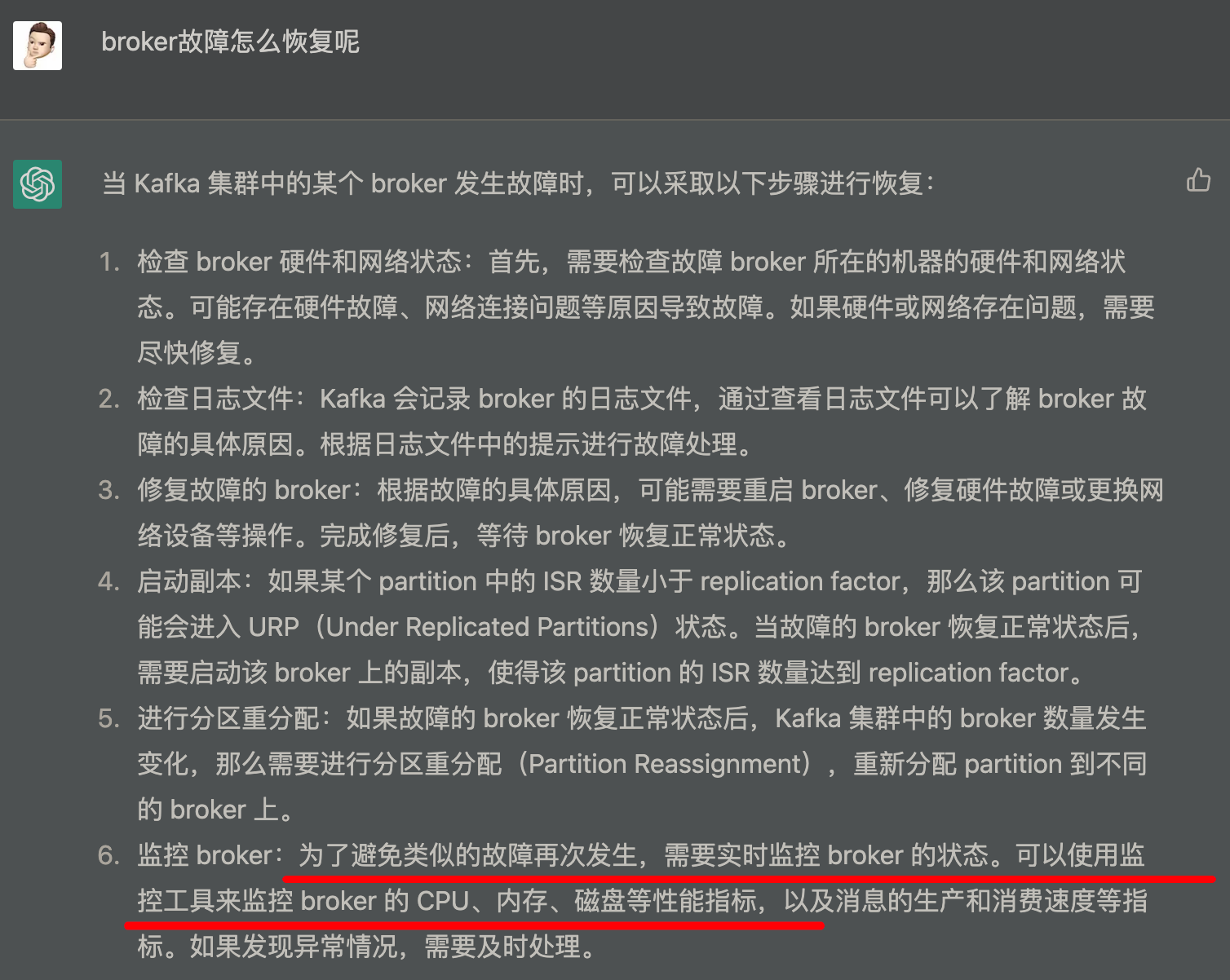
他好像什么都说了又好像什么都没说:
- 检查状态,没发现问题,Kafka 机器稳定运行,负载正常,网络畅通
- 得益于 Java 日志文件又臭又长,没看到什么故障原因
- 修复,不用修复了,Kafka 和 Zookeeper 进程都在,部分索引也在“正常”进入 ES,只是量少了点
- 副本,我们 Kafka 集群从开始运行秉承着能跑就行的原则,设置的副本数就是 1,🤦🏻♂️.jpg,现在贸然增减不现实,万一对目前正常处理的索引来个洗牌岂不 GG?
- 分区重新分配,我们最终解决问题的最终成功的原因应该就是这个
- 监控 broker,确实,经过这次教训,后面 Partition 和 Broker 的告警规则也要写起来了,装了 kafka_exporter 只为做看板给领导装逼,实际并没有任何告警策略,🤦🏻♂️.jpg
当然也不能全听我同事的,在 Google 一番后找到了一篇文章,有部分参考价值,直接看第三点——offline partition 异常处理
cd /data/kafka_2.11-2.2.1/bin && ./kafka-topics.sh --describe --zookeeper localhost:2181 | grep Leader
通过上述命令查看各个 topic 的状态,发现有 12 个 topic 的 Leader 是 -1,刚好就是一开始出现问题的那几个,这是不正常的。
Topic: Network_23_RS_Device Partition: 0 Leader: -1 Replicas: 1 Isr: 1
Topic: SDP_system Partition: 0 Leader: -1 Replicas: 1 Isr: 1
Topic: aduser_change Partition: 0 Leader: -1 Replicas: 1 Isr: 1
Topic: aduser_change1 Partition: 0 Leader: -1 Replicas: 1 Isr: 1
Topic: koala Partition: 0 Leader: -1 Replicas: 1 Isr: 1
Topic: ldap Partition: 0 Leader: -1 Replicas: 1 Isr: 1
Topic: network_23_clearpass Partition: 0 Leader: -1 Replicas: 1 Isr: 1
Topic: network_35_Aruba-system Partition: 0 Leader: -1 Replicas: 1 Isr: 1
Topic: network_35_zdns Partition: 0 Leader: -1 Replicas: 1 Isr: 1
Topic: nginx_test Partition: 0 Leader: -1 Replicas: 1 Isr: 1
Topic: nuc Partition: 0 Leader: -1 Replicas: 1 Isr: 1
Topic: prometheus Partition: 0 Leader: -1 Replicas: 1 Isr: 1
其实忙活一大下午,晚上另一个同事也过来看怎么解决,他的看法就是重启大法,我的观点是,现在已经出现了报错,不解决这些 offline 的 partition,万一重启起不来不是直接懵逼,到时候只能不管三七二十一,把整个目录删掉了。
于是接着查怎样处理这些 offline 的 partition:
cd /data/kafka_2.11-2.2.1/bin
# 进入到 Kafka 的安装目录
./zookeeper-shell.sh localhost:2181
# 使用自带的脚本连接到 Zookeeper
rmr /brokers/topics/network_35_zdns/partitions/0
rmr /brokers/topics/Network_23_RS_Device/partitions/0
rmr /brokers/topics/SDP_system/partitions/0
rmr /brokers/topics/aduser_change/partitions/0
rmr /brokers/topics/aduser_change1/partitions/0
rmr /brokers/topics/koala/partitions/0
rmr /brokers/topics/ldap/partitions/0
rmr /brokers/topics/network_23_clearpass/partitions/0
rmr /brokers/topics/network_35_Aruba-system/partitions/0
rmr /brokers/topics/nginx_test/partitions/0
rmr /brokers/topics/nuc/partitions/0
rmr /brokers/topics/prometheus/partitions/0
# 使用以上命令删除异常的 topic 的异常的 partition,有个问题这个 shell 秉承着 Linux 的设计理念,没有消息就是好消息
# 以至于执行删除命令并没有任何返回,于是我重新执行了一遍,然后它报,没有啥啥啥这个啥啥啥,舒适
删了之后,人家重启了,我们也准备命令重启了:
ps -aux | grep zooke | grep -v grep | grep -v exporter | grep -v dhcli | awk '{print $2}' | xargs kill -9
cd /data/kafka_2.11-2.2.1/bin && nohup ./zookeeper-server-start.sh ../config/zookeeper.properties &
cd /data/kafka_2.11-2.2.1/bin && nohup ./kafka-server-start.sh ../config/server.properties > kafka.log &
重启看日志,没有发现异常,打开 kafka-ui 的看板,offline 的数量全部回来了,URP 数量为 0。皆大欢喜,再去 Kibana 看,日志开始进来了。